Recent Posts
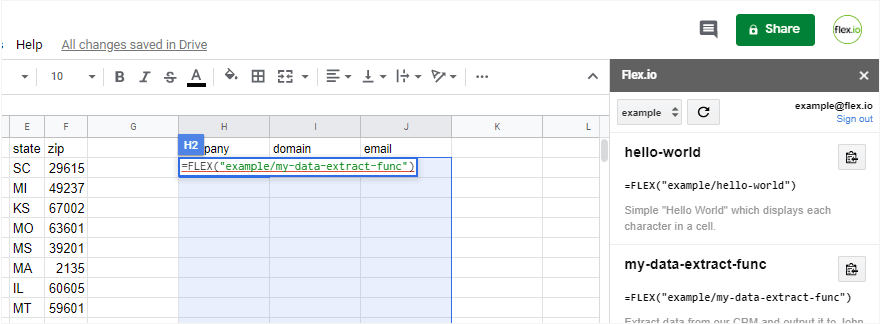
Integrating Web Services with Microsoft Excel and Google Sheets

The "Aha" Moment: How to Onboard an API Service and Get Active Users

Introducing Serverless Data Feeds

Share Data Without Sharing Credentials: Introducing Pipe-level Permissions

Lessons from the Data Ecosystem: Part 2

What We've Learned from Exploring the Data Ecosystem: Part 1

Improving Data Access: Getting Past Step One

Data Prep to Data Pipes: 5 Facets of a Data Project

Let a Thousand Data Silos Bloom

5 Steps to Faster Data Projects
What We've Learned from Exploring the Data Ecosystem: Part 1
As we’ve progressed through our private beta, one of the most fruitful activities has been talking with folks in different user communities about their data projects. This has had a profound impact on our product vision and roadmap (including a few major pivots).
A number of themes have come up again and again, so we thought it would be useful to distill this down to a few of the most significant points. We’ll cover the major themes in this post and then turn to some insights we’ve gained from different user communities in Part II.
The data ecosystem exists to generate new value from data
Before going further, it’s probably helpful to clarify what we see as the data ecosystem and what parts of it we’ve been exploring.
Generally, when I talk about the “data ecosystem”, I’m referring to the ever-growing set of connections and interactions between: 1) Data users, 2) Data sources, and 3) Data tools.
In my view, the data ecosystem encompasses the data derived from digital activity plus its usefulness and value to people. In other words, if a software application or a sensor generates a large data set, but no one ever examines or uses this data, it doesn’t really have any relevance to the broader ecosystem.

The data ecosystem is vast. In addition to the massive troves of private corporate data, there’s also an immense amount of open data being published every day. And with the explosion of Big Data and the Internet of Things, it’s clear that the makeup of the data ecosystem is rapidly expanding and changing.
Most of our research efforts have focused on areas that are related to Web-based data.
Since Flex.io originally grew out of our work with business users and IT departments, we started out looking at different B2B Software as a Service (SaaS) products used in this environment, such as Salesforce.com, Mailchimp, and Import.io. As a team we also have a large interest in open data and data for social good, so we’ve spent a lot of time talking with folks in this realm, including open data developers, data scientists and the ever-dynamic data journalist community.

Everyone is pushing around data, but for different reasons
No two data projects are ever exactly alike – in fact, the specifics can often vary greatly. We’ve certainly encountered this many times, whether through collaborating with IT departments on enterprise projects, or talking with data journalists about how they work with data.
But across the spectrum, most data projects do share a common workflow and other common traits.
It’s these common features—seen in context across a range of different communities—that tend to stand out the most. Here are three key observations we’ve come to appreciate.
There are a lot of touch points between different data tools, technologies and user groups
Data projects are a collaborative, team sport with different moving parts and multiple touch points. Data comes in from one place; results are generated and sent elsewhere. Different groups of users are often involved and different tools are needed to prepare and analyze the data.
Even the concepts themselves can have a lot of touch points and interconnections, such as data cleansing and data processing or Business Intelligence and data science.
Practically speaking, this means that no one system is sufficient to do all of the work on its own. Rather, decentralized data projects are the norm, and there will always be many different data sources and tools that need to be connected.
A key way to make data projects more efficient is to reduce the time and friction involved in dealing with these different touch points.
Adapting data is the central activity involved in making it useful
A lot of work goes into adapting data in order to generate new value from it. As DJ Patil has famously noted, “80% of the work in any data project is in cleaning the data.”
There’s a broad scope to how data can be adapted. For instance, a large integration project may be needed to adapt data from one system to another, such transforming multiple data sources to load them into an analytic tool. Or adapting data could involve cleaning up the content of the data itself, such as standardizing inconsistent values. It could even simply mean changing the data from one format into another.
In each case, the common denominator is that adapting the data turns it from raw materials into something that’s useful.
Connecting data sources increases their value and utility
Like baking bread or brewing beer, the combination of essential ingredients makes all the difference. This is why getting access to the relevant data is such an important step.
Connecting data sources may be as simple as moving data sets from point A to point B, or setting up access to an API. But even this can turn into a daunting challenge for anyone who lacks the coding chops or runs into an IT gatekeeper who’s unavailable to set up a data feed.
The good news is that connecting data sources can be very rewarding; the combined whole is often far more valuable than the individual parts.
. . .
These three points are at the core of what we’re working on with Flex.io: collaboration, adaptation and connection. We’re aiming make it easier to connect and combine data from the Web, transform this data and share it with colleagues or other data tools. In our next post, we’ll look at what we’ve learned from different user communities and their data projects.
Recent Posts
Integrating Web Services with Microsoft Excel and Google Sheets
The "Aha" Moment: How to Onboard an API Service and Get Active Users
Introducing Serverless Data Feeds
Share Data Without Sharing Credentials: Introducing Pipe-level Permissions
Lessons from the Data Ecosystem: Part 2