Recent Posts
Integrating Web Services with Microsoft Excel and Google Sheets

The "Aha" Moment: How to Onboard an API Service and Get Active Users

Introducing Serverless Data Feeds

Share Data Without Sharing Credentials: Introducing Pipe-level Permissions

Lessons from the Data Ecosystem: Part 2

What We've Learned from Exploring the Data Ecosystem: Part 1

Improving Data Access: Getting Past Step One

Data Prep to Data Pipes: 5 Facets of a Data Project

Let a Thousand Data Silos Bloom

5 Steps to Faster Data Projects
Introducing Serverless Data Feeds
It’s been a busy season of coding for our team. But with frigid temperatures and snow falling, what better time to hunker down and work on a major product update?
After many long winter nights, we have a new version of Flex.io in the wild that’s loaded with goodies.
With the latest release, we’re excited to introduce serverless data feeds. We’ve added a range of new capabilities for moving and processing data in the cloud. Our aim is to give developers a simple, scalable API to instantly build and run data feeds without needing to provision or manage infrastructure.
What are serverless data feeds?
Data feeds are simply a programmatic way to send data from here to there, like moving data from one app into another, bulk loading data into a repository or copying files between cloud storage accounts. Data feeds are the digital wiring that connects apps in the cloud and allows them to share data and files.
Serverless data feeds also deliver data, but without the cost of building and maintaining data infrastructure.
So, how do they work?
Serverless data feeds are deployed, executed and managed as an API-driven web service instead of using traditional server infrastructure. Similar to other API services, such as Twilio and Stripe, Flex.io handles all the traditional developer cost of setting up and maintaining servers, managing the feeds, and addressing scalability and performance.
Developers create and control their feeds using a specialized API, with the help of related SDKs and CLI tools. Since all the steps and logic are defined programmatically, developers can set up serverless data feeds with a few lines of code and manage them in source control.
In practice, this means that developers can build data feeds between web apps very quickly and with little or no overhead. If you want to set up a data feed to load call logs from Twilio into Elasticsearch, archive messages from Slack, or copy files from Box to Amazon S3, you can be up and running in minutes.
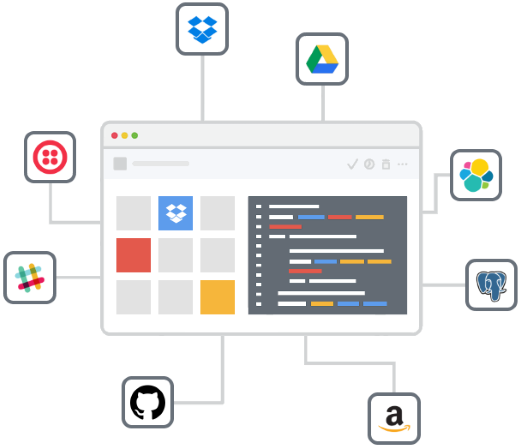
More control with specialized tools
Serverless technologies have seen rapid adoption in the past few years, with the rise of platforms such as AWS Lambda, Microsoft Azure and Google Cloud Platform. Here’s a great overview, if you’re not familiar with them.
Flex.io is not recreating a serverless platform by any means. As an API for data feeds, we’re providing a specialized toolkit for data delivery that gives developers greater control over their feeds.
For example, here are some out-of-the-box building blocks:
File Selection. You can add selection criteria to your data feeds so that they automatically load the correct files from an input source. This is useful for excluding files with invalid formats or content.
Routing. Conditional file routing is useful for sending your data and files to different destinations. You can automatically route the output of your feeds based on the criteria you specify.
Conversion. You can convert files from one format to another with a single command. This makes it easy to create data feeds that deliver output uniformly and in the correct format.
Batch Processing. You can add batch processing steps that act on each file in your feed. This is useful for updating file content, gathering metadata, or aggregating multiple files.
Of course, built-in tools can’t always meet every need. Not to worry – we’ve got you covered. For unique tasks, you can create custom steps using Javascript or Python.
Examples
The real magic gets started when you snap together a few operations to create a highly useful data feed that moves and processes data exactly the way you want and knocks an item off your development checklist.
To get the juices flowing, we’ve created a few examples that show different kinds of data feeds you can build:
Transfer files from Dropbox to Amazon S3. This is a basic example of a serverless data feed that transfers files between two cloud storage services. In this case, the data feed copies files from a folder in Dropbox to Amazon S3.
Convert a web-based CSV file to JSON. This shows a basic example of how to convert data on the web from a CSV to a JSON format. You can use this to reformat data loaded from a web page or an API request or use it as a conversion step in a serverless data feed.
Upload files to Amazon S3 via a web form. This shows how you can take a file from a web upload form and store it on Amazon S3. In this case, it also echoes back the new URL for the file. This is an example of how a feed can power a simple web component without the burden of server infrastructure.
You can try each of these examples by copying the code snippet that’s included. For additional examples, check out the Getting Started Guide as well as the SDK docs and API reference.
Feedback and recommendations
These days, we’re working on adding more built-in processing steps and filling out tutorials. We’d love to get your suggestions and recommendations on what you’d find most useful.
As always, we’re also eager to get your thoughts and feedback on the product. What’s working for you? What’s not?
Shoot us an email or give us a call and let us know. We’re eager to see what you’ll build!
Recent Posts
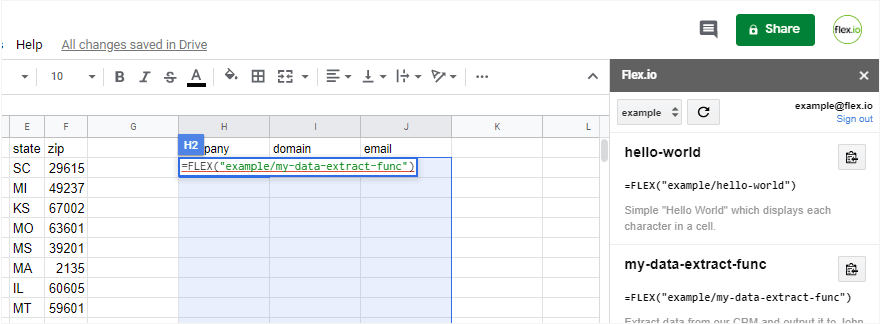
Integrating Web Services with Microsoft Excel and Google Sheets
The "Aha" Moment: How to Onboard an API Service and Get Active Users
Introducing Serverless Data Feeds
Share Data Without Sharing Credentials: Introducing Pipe-level Permissions
Lessons from the Data Ecosystem: Part 2