Recent Posts
Integrating Web Services with Microsoft Excel and Google Sheets

The "Aha" Moment: How to Onboard an API Service and Get Active Users

Introducing Serverless Data Feeds

Share Data Without Sharing Credentials: Introducing Pipe-level Permissions

Lessons from the Data Ecosystem: Part 2

What We've Learned from Exploring the Data Ecosystem: Part 1

Improving Data Access: Getting Past Step One

Data Prep to Data Pipes: 5 Facets of a Data Project

Let a Thousand Data Silos Bloom

5 Steps to Faster Data Projects
Improving Data Access: Getting Past Step One
In my previous post, I explored commonalities found in any given “data project.” Here we’ll run the first of the five gauntlets: data access.
A few moons ago, we visited a customer to talk about some analytics he wanted to explore. Big company. Big ideas. Big IT infrastructure. The idea sounded great and we were happy to help ‘em out.
“All we need is the XYZ file,” we said.
Long pause.
“Well, I can ask IT to pull an extract, but it will probably require an IT project. I’ll call you next year.”
The phrase “I need to talk to IT” is a common refrain in the corporate world and there are plenty of good reasons why data is a carefully controlled resource. In general, the bigger the enterprise, the more time and effort it takes to get your hands on the data you want.
On the flipside, data access can be an equally tricky problem in smaller organizations too. You may not have to confront the reams of policies, racks of servers or IT gatekeepers analyzing your request, but that lack of centralization and expertise can hurt just the same.
Files might be on someone’s desktop computer or Dropbox folder. It could be locked up in someone’s Salesforce.com login or only accessible via a cryptic API. Or, probably worst of all, you may be required to pay pennance to something called “FTP.”
If you have access to data yourself, via a direct database connection, a BI tool, or your SaaS login, you’re golden. But, more often than not, data projects are a team sport. Let’s consider the three primary parties that transfer data to one another:
- IT. With data projects, Information Technology folks usually have enough technical savvy and/or tools in their toolkit to get or give what they need (e.g., scripts, SQL, database access, institutional authority, stackoverflow).
- Machine. The rise of Skynet includes servers, databases, SaaS applications, terminators and other various components that primarily communicate via an API. 01110011 01101111 01101100 01101111.
- Business. I’m lumping in anyone here who can breathe but cannot write a SQL statement. The vast majority of people.
If we create an extremely sophisticated data-sharing-permutation-visualization, the bottlenecks become clear:

IT folks (and their machines) can typically handle their own data access requirements. But the other 99% of humans will often run into the following hurdles:
- The IT Handoff (technical to non-technical). Whether it’s a business user needing raw ERP tables or a startup CEO that needs access to her MySQL data, most data requests run through an IT person — who usually has 20 other things in his queue. The coordination between the gatekeepers and the end user is time consuming and requires a great deal of communication. Setting up a repeatable process is an even bigger time committment.
- The Cross-Colleague Collaboration (non-technical to non-technical). Often a business user needs to share data with another business user. This usually means emailing CSV attachments back and forth. Here you not only lose data context, but you can also bury information within long email threads. Having a business user setting up a refreshable data feed for a partner is pretty much out of the question.
- The API Odyssey (machine to non-technical). The Web itself is a vast database. Some of that data can be handled via scraping, some via CSV downloads and some via API. APIs are extremely powerful and more common than ever, but unless a business user has a pre-built interface, they are near impossible for a non-technical person to access.
When we set out to create Flex.io, we wondered how we could help make these data access issues more efficient for everyone. To do so, we worked on three key components:
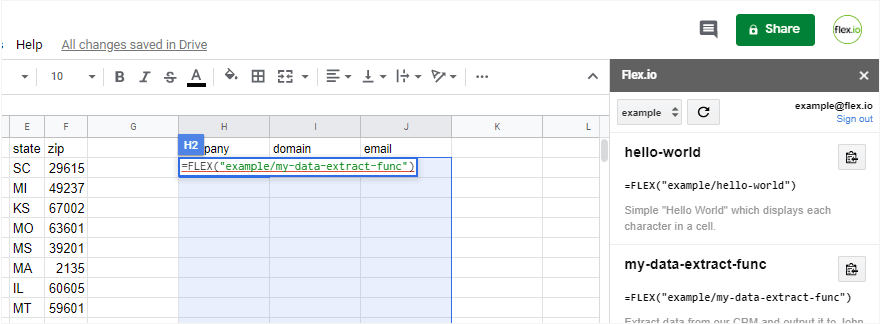
- Data Connectivity. Our goal is to make any data from any Web API accessible to anyone by simply allowing them to add “an input” or “an output”. No scripting necessary.
- Shared Work Environment. We allow any team to work together and make the data handoff seamless. So, for example, maybe an IT person authenticates with their MySQL connection while a teammate authenticates with their Dropbox account. In a shared project, the IT person can seamlessly schedule delivery of MySQL data to their teammate’s Dropbox folder.
- Repeatability. Static extracts and one-off files are fine, but Flex.io’s raison d’être is all about the flow and making data processes refreshable.
In the next post in this series, we’ll tackle Data Collaboration and explore how communication, sharing of business context and domain expertise are also critical for a successful data project implementation.
Image by: Logan Ingalls
Recent Posts
Integrating Web Services with Microsoft Excel and Google Sheets
The "Aha" Moment: How to Onboard an API Service and Get Active Users
Introducing Serverless Data Feeds
Share Data Without Sharing Credentials: Introducing Pipe-level Permissions
Lessons from the Data Ecosystem: Part 2