Recent Posts
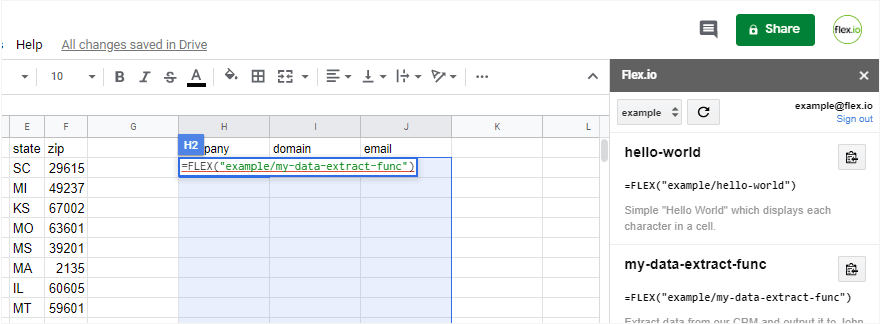
Integrating Web Services with Microsoft Excel and Google Sheets

The "Aha" Moment: How to Onboard an API Service and Get Active Users

Introducing Serverless Data Feeds

Share Data Without Sharing Credentials: Introducing Pipe-level Permissions

Lessons from the Data Ecosystem: Part 2

What We've Learned from Exploring the Data Ecosystem: Part 1

Improving Data Access: Getting Past Step One

Data Prep to Data Pipes: 5 Facets of a Data Project

Let a Thousand Data Silos Bloom

5 Steps to Faster Data Projects
Data Prep to Data Pipes: 5 Facets of a Data Project
At this point, we’ve all heard the news.
Data is growing at an exponential rate. Data is the new oil. Data is a strategic advantage. Data is big. Data is small. Certainly Goldilocks believes her porridge data is jusssst right.
Meh. Data is simply a means to an end.
So, how does one go from “data is super awesome” to actually getting value from it? Well, it’s a long and winding road, often called “a data project.”
I recently came across a nice article discussing the process of building a predictive application with machine learning. Developing predictive apps is not my personal specialty, but it’s easy to see how it follows the common stages of other data projects of almost any shape and size. This article breaks down the data science process into three phases:
Data engineering > Data Intelligence > Deployment
This is a really nice, sleek encapsulation. However, let me take a stab at expanding it just a bit since the “data engineering” phase has a lot going on. So, stepping back just a tad, let me suggest five commonalities between Every. Data. Project. (drumroll please!):
- Data Access (Where’s the data?). One of the big barriers to getting a data project started is simply obtaining the data. There can be plenty of bottlenecks here, from IT schedules to Web silos to API access to waiting on a colleague’s email attachment.
- Data Exploration (What am I looking at?). Once the data is finally in hand, you need to get your arms around it. One good method is to do some data profiling, like looking at date ranges or identifying empty columns.
- Data Collaboration (Who can help me?). Data projects are typically a team sport. Multiple people, with different domain expertise, come together to get the job done. Communication and data context matter.
- Data Preparation (Why is this so messy?). The ol’ data trope bears repeating: “80% of the work in any data project is in cleaning the data.” It can take a lot of time to clean up data structures or reformat fields into something usable. Once clean up is done, the “Data Intelligence” phase can begin and insights can finally be gleaned.
- Data Deployment (How can I do this again?). Phew, we made it! But wait, how can we get this same insight again, just refreshed with next week’s data? “Operationalizing” a process may mean starting a new project and encapsulating your work in a script or macro.
Data projects — getting from Data Access all the way to Data Deployment — can take some time and can involve a fair share of hand-wringing. Ask anyone who had been involved in a data project and they’ll shake their heads knowingly.
When our team envisioned Flex.io, these were the folks we were thinking about. How can we help people get through each phase of the data project as quickly as possible. What are the key bottlenecks and how do you break through them? How do you turn months into days? How can you give data superpowers to ordinary people? The good news — we think we have some answers. :-)
In upcoming posts, I’ll look at each of these phases in more detail and explore some of the common problems and solutions for each.
In the meantime, let me know in the comments if you agree or think I’m off my rocker. Until then!
Image by: Phillipe Put
Recent Posts
Integrating Web Services with Microsoft Excel and Google Sheets
The "Aha" Moment: How to Onboard an API Service and Get Active Users
Introducing Serverless Data Feeds
Share Data Without Sharing Credentials: Introducing Pipe-level Permissions
Lessons from the Data Ecosystem: Part 2